Yuchen Zhu 朱雨宸
Machine Learning PhD @ Georgia Tech 🍀

Photo credit to Sichen. Grand Canyon.
Hi, I am Yuchen Zhu, a 3rd year Machine Learning PhD at  Georgia Tech, advised by Molei Tao and Yongxin Chen.
Georgia Tech, advised by Molei Tao and Yongxin Chen.
I work on generative AI. My current research centers on building the next generation of LLMs with greater efficiency and capability, through the development of diffusion language models (dLLM). I also work on diffusion models and their multimodal variants for vision and language.
During Summer 2026, I am a Research Scientist Intern at  NVIDIA, exploring efficient frontier LLMs.
NVIDIA, exploring efficient frontier LLMs.
During Spring 2026, I was fortunate to work with Jiuxiang Gu and Jing Shi as a Research Scientist Intern at  Adobe Research, building efficient & capable dLLMs at scale.
Adobe Research, building efficient & capable dLLMs at scale.
I graduated with BS in Mathematics (Honors) from  NYU Shanghai and MA in Statistics from
NYU Shanghai and MA in Statistics from  Yale University. My research started in applied mathematics, optimal control and RL theory, and has since evolved toward generative AI.
Yale University. My research started in applied mathematics, optimal control and RL theory, and has since evolved toward generative AI.
You can find more details in my CV here.
📧 Feel free to reach out: yzhu738@gatech.edu / yuchenzhu0226@gmail.com
Updates
- 06/2026 FLARE is online! Check out our new study on how to build SOTA dLLMs from LLMs with hybrid-attention!
- 05/2026 DMPO got Spotlight (< 2.2%) at ICML 2026! Code is available here. See you in Seoul!
- 05/2026 5 papers @ ICML 2026: LaViDa-R1, Discrete ASBS, DMPO, PRISM, and Rethinking Diffusion RL.
- 02/2026 Rethinking Diffusion RL is online! Importance of likelihood estimation in diffusion model RL is more than you think.
- 01/2026 I start as a Research Scientist Intern at
 Adobe Research, working on post-training of diffusion LLMs.
Adobe Research, working on post-training of diffusion LLMs. - 10/2025 DMPO is online! Check out a completely new RL paradigm of diffusion LLMs for effective post-training! Code is available here.
- 10/2025 TR2-D2 is online! Discover the SOTA method for finetuning MDM for bio seqs design with tree search + off-policy RL!
- 10/2025 PDNS is online! See our new upgrade of MDNS with additional proximal gradient steps!
- 09/2025 MDNS and Discrete Fast Solvers got accepted to NeurIPS 2025, see you in San Diego!
- 08/2025 MDNS is online! Come find out our new work on ways to doing RL with masked discrete diffusion!
- 06/2025 Mimicking or Reasoning is public! Check out our new work on evaluating MM-ICL for VLM reasoners!
- 06/2025 Diffuse Everything is online! Check out our new work on multimodal diffusion models on native state spaces!
- 05/2025 Learning to Stop and Diffuse Everything got accepted to ICML 2025, see you in Vancouver!
- 04/2025 I wrote a new blog on how group structures aid generative modeling of manifold data.
- 02/2025 Check out my new work on fast high-order samplers for discrete diffusion models!
- 01/2025 TDM and STEM got accepted to ICLR 2025, see you in Singapore!
- 10/2024 New work Plug-and-Play Controllable Generation for Discrete Masked Models is online!
- 05/2024 New work Trivialized Momentum Facilitates Diffusion Generative Modeling on Lie Groups is online!
- 04/2024 New work Quantum state generation with Structure Preserving Diffusion Model is online!
Selected Publications
-
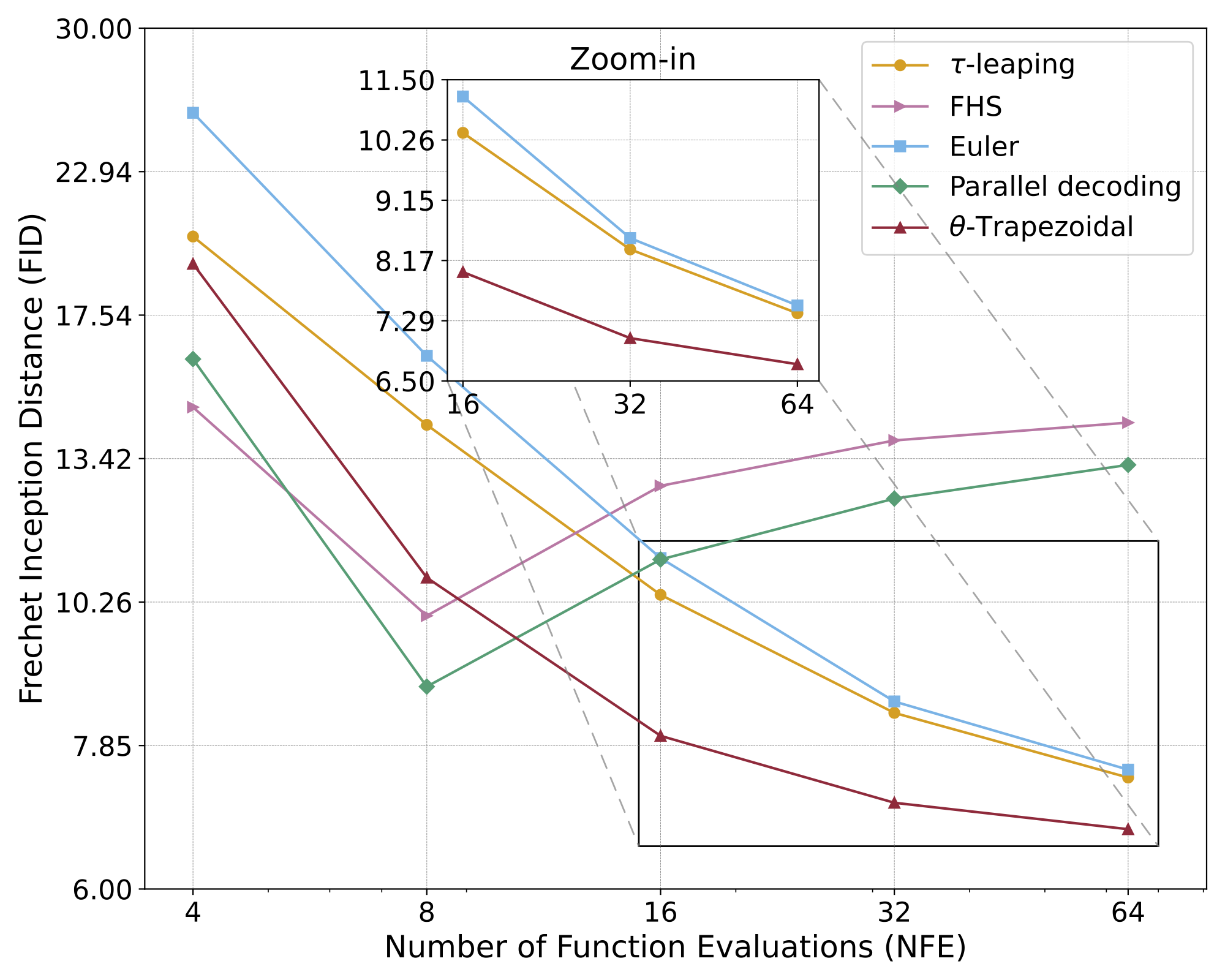 Fast Solvers for Discrete Diffusion Models: Theory and Applications of High-Order AlgorithmsNeurIPS 2025dllm · inference
Fast Solvers for Discrete Diffusion Models: Theory and Applications of High-Order AlgorithmsNeurIPS 2025dllm · inference







Talks
- 03/2026 INFORMS Optimization Society Conference 2026
- 09/2025 GT ML Student Conference
- 08/2025 MolSS Reading Group
- 11/2024 GT ML Student Seminar
- 10/2024 SIAM MDS 2024
- 04/2024 Southeast ACM Student Workshop 2024